Merging, Joining, Concatenating, and Comparing DataFrames in Pandas Codes With Pankaj
In data analysis and manipulation with Pandas, merging, joining, concatenating, and comparing are essential operations. These operations allow you to combine datasets, fill missing values, and compare data efficiently. In this tutorial, we’ll explore each of these operations in detail:
Concatenating DataFrames using Pandas
pandas.concat()
The pandas.concat() function allows you to concatenate pandas objects along either rows or columns. It is a flexible tool for combining datasets and can handle optional set logic along other axes.
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=None)Parameters:
- objs: A sequence or mapping of Series or DataFrame objects to concatenate.
- axis: Axis to concatenate along. 0 for rows, 1 for columns.
- join: Specifies how to handle indexes on other axes. Can be ‘inner’ or ‘outer’.
- ignore_index: If True, the resulting axis will be labeled 0, 1, …, n — 1.
- keys: Adds a hierarchical index using the passed keys as the outermost level.
- verify_integrity: Checks whether the new concatenated axis contains duplicates.
- sort: Sorts non-concatenation axis if it is not already aligned.
- copy: If False, do not copy data unnecessarily.
Examples:
Let’s go through various examples to understand the usage of pandas.concat():
Example 1: Combine Two Series
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
result = pd.concat([s1, s2])
print(result)//output
0 a
1 b
0 c
1 d
dtype: objectExample 2: Clear Existing Index and Reset It
result = pd.concat([s1, s2], ignore_index=True)
print(result)//output
0 a
1 b
2 c
3 d
dtype: objectExample 3: Add a Hierarchical Index
result = pd.concat([s1, s2], keys=['s1', 's2'])
print(result)s1 0 a
1 b
s2 0 c
1 d
dtype: objectExample 4: Combine Two DataFrames
df1 = pd.DataFrame([['a', 1], ['b', 2]], columns=['letter', 'number'])
df2 = pd.DataFrame([['c', 3], ['d', 4]], columns=['letter', 'number'])
result = pd.concat([df1, df2])
print(result) //output
letter number
0 a 1
1 b 2
0 c 3
1 d 4Example 5: Combine DataFrames with Overlapping Columns
df3 = pd.DataFrame([['c', 3, 'cat'], ['d', 4, 'dog']], columns=['letter', 'number', 'animal'])
result = pd.concat([df1, df3], sort=False)
print(result)//output
letter number animal
0 a 1 NaN
1 b 2 NaN
0 c 3 cat
1 d 4 dogExample 6: Combine DataFrames and Return Only Shared Columns
result = pd.concat([df1, df3], join="inner")
print(result)//output
letter number
0 a 1
1 b 2
0 c 3
1 d 4Example 7: Combine DataFrames Horizontally
df4 = pd.DataFrame([['bird', 'polly'], ['monkey', 'george']], columns=['animal', 'name'])
result = pd.concat([df1, df4], axis=1)
print(result)//output
letter number animal name
0 a 1 bird polly
1 b 2 monkey georgeExample 8: Prevent Including Duplicate Index Values
df5 = pd.DataFrame([1], index=['a'])
df6 = pd.DataFrame([2], index=['a'])
result = pd.concat([df5, df6], verify_integrity=True)
print(result)//output
ValueError: Indexes have overlapping values: ['a']Example 9: Append a Single Row to a DataFrame
df7 = pd.DataFrame({'a': 1, 'b': 2}, index=[0])
new_row = pd.Series({'a': 3, 'b': 4})
result = pd.concat([df7, new_row.to_frame().T], ignore_index=True)
print(result) //output
a b
0 1 2
1 3 4Exmaple :
import pandas as pd
# codeswithpankaj.com
# Define DataFrame 1 with Indian food
df1 = pd.DataFrame(
{
"Dish": ["Biryani", "Butter Chicken", "Paneer Tikka", "Masala Dosa"],
"Main Ingredient": ["Rice", "Chicken", "Paneer", "Dosa Batter"],
"Spices": ["Biryani Masala", "Butter, Tomato", "Tandoori Masala", "Masala Mix"],
"Region": ["Hyderabad", "Punjab", "North India", "South India"],
},
index=[0, 1, 2, 3],
)
# Define DataFrame 2 with more Indian food
df2 = pd.DataFrame(
{
"Dish": ["Samosa", "Chole Bhature", "Aloo Paratha", "Rasgulla"],
"Main Ingredient": ["Potato, Peas", "Chickpeas", "Potato", "Chhena"],
"Spices": ["Chaats Masala", "Chole Masala", "Cumin, Coriander", "Cardamom"],
"Region": ["North India", "Punjab", "Punjab", "West Bengal"],
},
index=[4, 5, 6, 7],
)
# Define DataFrame 3 with more Indian food
df3 = pd.DataFrame(
{
"Dish": ["Vada Pav", "Pav Bhaji", "Dhokla", "Jalebi"],
"Main Ingredient": ["Potato, Bread", "Mixed Vegetables", "Rice Flour", "Maida"],
"Spices": ["Garlic Chutney", "Pav Bhaji Masala", "Green Chili", "Saffron"],
"Region": ["Maharashtra", "Maharashtra", "Gujarat", "North India"],
},
index=[8, 9, 10, 11],
)
# Concatenate the DataFrames
frames = [df1, df2, df3]
result = pd.concat(frames)
# Display the result
print(result) Dish Main Ingredient Spices Region
0 Biryani Rice Biryani Masala Hyderabad
1 Butter Chicken Chicken Butter, Tomato Punjab
2 Paneer Tikka Paneer Tandoori Masala North India
3 Masala Dosa Dosa Batter Masala Mix South India
4 Samosa Potato, Peas Chaats Masala North India
5 Chole Bhature Chickpeas Chole Masala Punjab
6 Aloo Paratha Potato Cumin, Coriander Punjab
7 Rasgulla Chhena Cardamom West Bengal
8 Vada Pav Potato, Bread Garlic Chutney Maharashtra
9 Pav Bhaji Mixed Vegetables Pav Bhaji Masala Maharashtra
10 Dhokla Rice Flour Green Chili Gujarat
11 Jalebi Maida Saffron North IndiaGenerate a table image that includes the row and column indices, we can use the matplotlib.table.Table class along with the Matplotlib library. Here's how you can do it:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.table import Table
# Define DataFrame 1 with Indian food
df1 = pd.DataFrame(
{
"Dish": ["Biryani", "Butter Chicken", "Paneer Tikka", "Masala Dosa"],
"Main Ingredient": ["Rice", "Chicken", "Paneer", "Dosa Batter"],
"Spices": ["Biryani Masala", "Butter, Tomato", "Tandoori Masala", "Masala Mix"],
"Region": ["Hyderabad", "Punjab", "North India", "South India"],
},
index=[0, 1, 2, 3],
)
# Define DataFrame 2 with more Indian food
df2 = pd.DataFrame(
{
"Dish": ["Samosa", "Chole Bhature", "Aloo Paratha", "Rasgulla"],
"Main Ingredient": ["Potato, Peas", "Chickpeas", "Potato", "Chhena"],
"Spices": ["Chaats Masala", "Chole Masala", "Cumin, Coriander", "Cardamom"],
"Region": ["North India", "Punjab", "Punjab", "West Bengal"],
},
index=[4, 5, 6, 7],
)
# Define DataFrame 3 with more Indian food
df3 = pd.DataFrame(
{
"Dish": ["Vada Pav", "Pav Bhaji", "Dhokla", "Jalebi"],
"Main Ingredient": ["Potato, Bread", "Mixed Vegetables", "Rice Flour", "Maida"],
"Spices": ["Garlic Chutney", "Pav Bhaji Masala", "Green Chili", "Saffron"],
"Region": ["Maharashtra", "Maharashtra", "Gujarat", "North India"],
},
index=[8, 9, 10, 11],
)
# Concatenate the DataFrames
frames = [df1, df2, df3]
result = pd.concat(frames)
# Convert the DataFrame to a list of lists for the table
data = [result.columns.tolist()] + result.values.tolist()
# Create a Matplotlib figure and axis
fig, ax = plt.subplots(figsize=(10, 6))
# Create the table
table = ax.table(cellText=data, loc='center', cellLoc='center', colWidths=[0.2]*len(result.columns))
# Adjust the font size
table.auto_set_font_size(False)
table.set_fontsize(10)
# Hide axes
ax.axis('off')
# Add a title
plt.title('Concatenated DataFrame')
# Show the table
plt.show()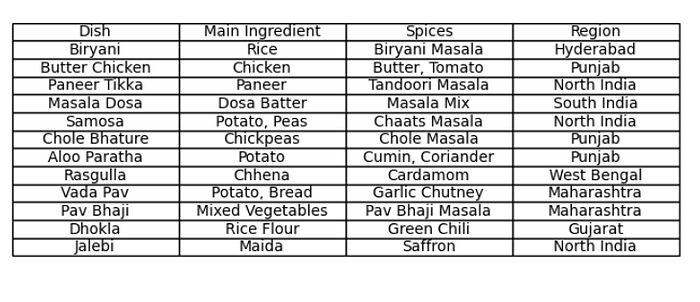
pandas.DataFrame.join()
Let’s start by understanding the parameters and then move on to practical examples.
Parameters:
- other: DataFrame, Series, or a list containing any combination of them. The index should be similar to one of the columns in the caller DataFrame. If a Series is passed, its name attribute must be set, and that will be used as the column name in the resulting joined DataFrame.
- on: String, list of strings, or array-like, optional. Column or index level name(s) in the caller to join on the index in the other DataFrame, otherwise joins index-on-index. It functions similar to an Excel VLOOKUP operation.
- how: {‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘left’. Specifies how to handle the operation of the two objects during the join.
- lsuffix: String, default ‘’. Suffix to use from the left frame’s overlapping columns.
- rsuffix: String, default ‘’. Suffix to use from the right frame’s overlapping columns.
- sort: Boolean, default False. Orders the result DataFrame lexicographically by the join key.
- validate: String, optional. If specified, checks if the join is of the specified type.
Examples:
Let’s walk through some examples to understand how to use DataFrame.join():
import pandas as pd
# Indian Food DataFrame
indian_food = pd.DataFrame({
'dish': ['Butter Chicken', 'Biryani', 'Samosa', 'Paneer Tikka', 'Masala Dosa'],
'main_ingredient': ['Chicken', 'Rice', 'Potato', 'Paneer', 'Potato'],
'region': ['North India', 'South India', 'North India', 'North India', 'South India']
})
# Indian Food Ingredients DataFrame
ingredients = pd.DataFrame({
'dish': ['Butter Chicken', 'Biryani', 'Samosa'],
'spice_level': ['Medium', 'Spicy', 'Mild']
})
# Join DataFrames using their indexes
result = indian_food.join(ingredients.set_index('dish'), lsuffix='_indian_food', rsuffix='_ingredients')
print(result) dish_indian_food main_ingredient region spice_level
0 Butter Chicken Chicken North India Medium
1 Biryani Rice South India Spicy
2 Samosa Potato North India Mild
3 Paneer Tikka Paneer North India NaN
4 Masala Dosa Potato South India NaNUsing non-unique key values shows how they are matched.
import pandas as pd
# Indian Food DataFrame with non-unique key values
indian_food_non_unique = pd.DataFrame({
'dish': ['Butter Chicken', 'Biryani', 'Biryani', 'Paneer Tikka', 'Butter Chicken'],
'main_ingredient': ['Chicken', 'Rice', 'Rice', 'Paneer', 'Chicken'],
'region': ['North India', 'South India', 'North India', 'North India', 'North India']
})
# Indian Food Ingredients DataFrame
ingredients = pd.DataFrame({
'dish': ['Butter Chicken', 'Biryani', 'Biryani'],
'spice_level': ['Medium', 'Spicy', 'Spicy']
})
# Join DataFrames using their indexes and specifying validation
result = indian_food_non_unique.join(ingredients.set_index('dish'), on='dish', validate='m:1')
print(result) dish main_ingredient region spice_level
0 Butter Chicken Chicken North India Medium
1 Biryani Rice South India Spicy
2 Biryani Rice North India Spicy
3 Paneer Tikka Paneer North India NaN
4 Butter Chicken Chicken North India MediumConcatenating Series and DataFrame in Pandas
1. Concatenating Series with DataFrame
When concatenating a Series with a DataFrame, the Series will be transformed into a DataFrame with the column name as the name of the Series.
import pandas as pd
s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
result = pd.concat([df1, s1], axis=1)
print(result)2. Concatenating Unnamed Series
Unnamed Series will be numbered consecutively when concatenated with a DataFrame.
s2 = pd.Series(["_0", "_1", "_2", "_3"])
result = pd.concat([df1, s2, s2, s2], axis=1)
print(result)3. Using ignore_index=True
Setting ignore_index=True will drop all name references, resulting in columns being numbered consecutively.
result = pd.concat([df1, s1], axis=1, ignore_index=True)
print(result)4. Resulting keys
The keys argument adds another axis level to the resulting index or column, creating a MultiIndex.
result = pd.concat(frames, keys=["x", "y", "z"])
print(result)
# Accessing data from a specific key
print(result.loc["y"])5. Overriding Column Names with Keys
The keys argument can override the column names when creating a new DataFrame based on existing Series.
s3 = pd.Series([0, 1, 2, 3], name="foo")
s4 = pd.Series([0, 1, 2, 3])
s5 = pd.Series([0, 1, 4, 5])
print(pd.concat([s3, s4, s5], axis=1))
print(pd.concat([s3, s4, s5], axis=1, keys=["red", "blue", "yellow"]))6. Concatenating a dictionary of DataFrames
You can pass a dictionary of DataFrames to pd.concat(), where each key corresponds to a separate level in the resulting MultiIndex.
pieces = {"x": df1, "y": df2, "z": df3}
result = pd.concat(pieces)
print(result)
# Specifying keys
result = pd.concat(pieces, keys=["z", "y"])
print(result)7. Appending rows to a DataFrame
If you have a Series representing a single row that you want to append to a DataFrame, you can convert the row into a DataFrame and use pd.concat().
s2 = pd.Series(["X0", "X1", "X2", "X3"], index=["A", "B", "C", "D"])
result = pd.concat([df1, s2.to_frame().T], ignore_index=True)
print(result)Example demonstrating the concatenation of Series and DataFrame objects using Indian food data:
import pandas as pd
# Sample DataFrame with Indian food data
indian_food_data = pd.DataFrame({
'dish_name': ['Biryani', 'Butter Chicken', 'Masala Dosa', 'Paneer Tikka', 'Samosa'],
'main_ingredient': ['Rice', 'Chicken', 'Potato', 'Paneer', 'Potato'],
'region': ['Hyderabad', 'Punjab', 'South India', 'North India', 'North India']
}
# Sample Series with additional information
additional_info_series = pd.Series(["Spicy", "Creamy", "Savoury", "Vegetarian", "Crispy"], name="attributes")
# Example 1: Concatenating Series with DataFrame
result_concat_series_df = pd.concat([indian_food_data, additional_info_series], axis=1)
print("Concatenating Series with DataFrame:")
print(result_concat_series_df)
# Sample Series without names
unnamed_series = pd.Series(["Rich", "Flavorful", "Delicious", "Healthy", "Fried"])
# Example 2: Concatenating Unnamed Series with DataFrame
result_concat_unnamed_series = pd.concat([indian_food_data, unnamed_series, unnamed_series, unnamed_series], axis=1)
print("\nConcatenating Unnamed Series with DataFrame:")
print(result_concat_unnamed_series)
# Example 3: Using ignore_index=True
result_ignore_index = pd.concat([indian_food_data, additional_info_series], axis=1, ignore_index=True)
print("\nUsing ignore_index=True:")
print(result_ignore_index)
# Example 4: Resulting keys
frames = [indian_food_data.sample(4), indian_food_data.sample(4), indian_food_data.sample(4)]
result_keys = pd.concat(frames, keys=["South", "North", "West"])
print("\nResulting keys:")
print(result_keys)
print("\nAccessing data from a specific key:")
print(result_keys.loc["South"])
# Example 5: Overriding Column Names with Keys
s_additional_info1 = pd.Series(["Spicy", "Creamy", "Savoury", "Vegetarian", "Crispy"], name="attributes")
s_additional_info2 = pd.Series(["Hot", "Tender", "Tangy", "Protein-rich", "Flaky"], name="attributes")
s_additional_info3 = pd.Series(["Aromatic", "Juicy", "Crisp", "Calcium-rich", "Crunchy"], name="attributes")
result_keys_attributes = pd.concat([s_additional_info1, s_additional_info2, s_additional_info3], axis=1, keys=["Region1", "Region2", "Region3"])
print("\nOverriding Column Names with Keys:")
print(result_keys_attributes)
# Example 6: Concatenating a dictionary of DataFrames
pieces = {"North": indian_food_data.sample(2), "South": indian_food_data.sample(2), "East": indian_food_data.sample(2)}
result_dict = pd.concat(pieces)
print("\nConcatenating a dictionary of DataFrames:")
print(result_dict)
# Specifying keys
result_dict_with_keys = pd.concat(pieces, keys=["North", "South", "East"])
print("\nSpecifying keys:")
print(result_dict_with_keys)
# Example 7: Appending rows to a DataFrame
new_row_series = pd.Series(["Flavourful", "Marinated", "Light", "Non-vegetarian", "Crunchy"], index=["dish_name", "main_ingredient", "region", "attributes", "New_Column"])
result_append_row = pd.concat([indian_food_data, new_row_series.to_frame().T], ignore_index=True)
print("\nAppending rows to a DataFrame:")
print(result_append_row)Concatenating Series with DataFrame:
dish_name main_ingredient region attributes
0 Biryani Rice Hyderabad Spicy
1 Butter Chicken Chicken Punjab Creamy
2 Masala Dosa Potato South India Savoury
3 Paneer Tikka Paneer North India Vegetarian
4 Samosa Potato North India Crispy
Concatenating Unnamed Series with DataFrame:
dish_name main_ingredient region 0 1 2
0 Biryani Rice Hyderabad Rich Flavorful Delicious
1 Butter Chicken Chicken Punjab Flavorful Delicious Delicious
2 Masala Dosa Potato South India Delicious Delicious Delicious
3 Paneer Tikka Paneer North India Healthy Healthy Healthy
4 Samosa Potato North India Fried Fried Fried
Using ignore_index=True:
0 1 2 3 4
0 Biryani Rice Hyderabad Spicy NaN
1 Butter Chicken Chicken Punjab Creamy NaN
2 Masala Dosa Potato South India Savoury NaN
3 Paneer Tikka Paneer North India Vegetarian NaN
4 Samosa Potato North India Crispy NaN
Resulting keys:
dish_name main_ingredient region
South 0 Butter Chicken Chicken Punjab
1 Paneer Tikka Paneer North India
North 0 Butter Chicken Chicken Punjab
1 Paneer Tikka Paneer North India
West 0 Samosa Potato North India
1 Butter Chicken Chicken Punjab
Accessing data from a specific key:
dish_name main_ingredient region
0 Butter Chicken Chicken Punjab
1 Paneer Tikka Paneer North India
Overriding Column Names with Keys:
Region1 Region2 Region3
0 Spicy Hot Aromatic
1 Creamy Tender Juicy
2 Savoury Tangy Crisp
3 Vegetarian Protein-rich Calcium-rich
4 Crispy Flaky Crunchy
Concatenating a dictionary of DataFrames:
dish_name main_ingredient region
North 0 Biryani Rice Hyderabad
1 Samosa Potato North India
South 0 Biryani Rice Hyderabad
1 Samosa Potato North India
East 0 Biryani Rice Hyderabad
1 Samosa Potato North India
Specifying keys:
dish_name main_ingredient region
North Biryani Rice Hyderabad
Samosa Potato North India
South Biryani Rice Hyderabad
Samosa Potato North India
East Biryani Rice Hyderabad
Samosa Potato North India
Appending rows to a DataFrame:
dish_name main_ingredient region attributes New_Column
0 Biryani Rice Hyderabad Spicy NaN
1 Butter Chicken Chicken Punjab Creamy NaN
2 Masala Dosa Potato South India Savoury NaN
3 Paneer Tikka Paneer North India Vegetarian NaN
4 Samosa Potato North India Crispy NaN
5 Paneer Tikka Marinated North India Light NaNPandas Merge
It’s common to combine datasets based on common columns or indices. pandas.merge() is a powerful function in the Pandas library that allows you to perform this task efficiently. This tutorial will cover the various parameters of pandas.merge() and provide examples to demonstrate its usage.
pandas.merge(
left,
right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=False,
suffixes=('_x', '_y'),
copy=None,
indicator=False,
validate=None
)Parameters
- left, right: DataFrame or named Series objects to merge.
- how: Type of merge to be performed. Options include
'left','right','outer','inner', and'cross'. - on: Column or index level names to join on.
- left_on, right_on: Column or index level names to join on in the left and right DataFrames, respectively.
- left_index, right_index: Use the index from the left or right DataFrame as the join key(s).
- sort: Sort the join keys lexicographically in the result DataFrame.
- suffixes: A length-2 sequence indicating the suffixes to add to overlapping column names.
- copy: If
False, avoid copy if possible. - indicator: If
True, adds a column to the output DataFrame with information on the source of each row. - validate: If specified, checks if merge is of specified type.
Example 1: Basic Merge
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'], 'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'], 'value': [5, 6, 7, 8]})
merged_df = df1.merge(df2, left_on='lkey', right_on='rkey')
print(merged_df)Example 2: Merge with Suffixes
df1 = pd.DataFrame({'lkey': ['foo', 'bar'], 'value': [1, 2]})
df2 = pd.DataFrame({'rkey': ['foo', 'baz'], 'value': [3, 4]})
merged_df = df1.merge(df2, left_on='lkey', right_on='rkey', suffixes=('_left', '_right'))
print(merged_df)Example 3: Cross Merge
df1 = pd.DataFrame({'left': ['foo', 'bar']})
df2 = pd.DataFrame({'right': [7, 8]})
cross_merged_df = df1.merge(df2, how='cross')
print(cross_merged_df)Types of Merges
1. One-to-One Merge
In a one-to-one merge, two DataFrame objects are joined based on their indexes, which must contain unique values.
2. Many-to-One Merge
In a many-to-one merge, a unique index from one DataFrame is joined to one or more columns in another DataFrame.
3. Many-to-Many Merge
In a many-to-many merge, columns from one DataFrame are joined with columns from another DataFrame.
merge() Function Syntax
The syntax of the merge() function in Pandas is as follows:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)Examples :
One-to-One Merge
left = pd.DataFrame({"key": ["K0", "K1", "K2", "K3"], "A": ["A0", "A1", "A2", "A3"], "B": ["B0", "B1", "B2", "B3"]})
right = pd.DataFrame({"key": ["K0", "K1", "K2", "K3"], "C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]})
result = pd.merge(left, right, on="key")
print(result)Many-to-One Merge
left = pd.DataFrame({"key1": ["K0", "K0", "K1", "K2"], "key2": ["K0", "K1", "K0", "K1"], "A": ["A0", "A1", "A2", "A3"], "B": ["B0", "B1", "B2", "B3"]})
right = pd.DataFrame({"key1": ["K0", "K1", "K1", "K2"], "key2": ["K0", "K0", "K0", "K0"], "C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]})
result = pd.merge(left, right, how="left", on=["key1", "key2"])
print(result)Many-to-Many Merge
left = pd.DataFrame({"A": [1, 2], "B": [2, 2]})
right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
result = pd.merge(left, right, on="B", how="outer")
print(result)Example :
import pandas as pd
# Sample Indian food dataset
left_indian_food = pd.DataFrame({
"dish": ["butter chicken", "paneer tikka", "samosa", "dal makhani"],
"main_ingredient": ["chicken", "paneer", "potato", "lentils"],
"region": ["Punjab", "North India", "North India", "Punjab"]
})
right_indian_food = pd.DataFrame({
"dish": ["butter chicken", "paneer tikka", "samosa", "naan"],
"spicy_level": ["medium", "mild", "medium", "none"],
"region": ["Punjab", "North India", "North India", "North India"]
})
# One-to-One Merge
result_one_to_one = pd.merge(left_indian_food, right_indian_food, on="dish")
# Many-to-One Merge
result_many_to_one = pd.merge(left_indian_food, right_indian_food, how="left", on="region")
# Many-to-Many Merge
result_many_to_many = pd.merge(left_indian_food, right_indian_food, on="region", how="outer")
print("One-to-One Merge:")
print(result_one_to_one)
print("\nMany-to-One Merge:")
print(result_many_to_one)
print("\nMany-to-Many Merge:")
print(result_many_to_many)One-to-One Merge :
dish main_ingredient region spicy_level
0 butter chicken chicken Punjab medium
1 paneer tikka paneer Punjab mild
2 samosa potato Haryana mediumMany-to-One Merge :
dish main_ingredient region spicy_level
0 butter chicken chicken Punjab medium
1 paneer tikka paneer Punjab mild
2 samosa potato North India medium
3 dal makhani lentils Punjab NaNMany-to-Many Merge :
dish_x main_ingredient_x region dish_y spicy_level
0 butter chicken chicken Punjab butter chicken medium
1 butter chicken chicken Punjab paneer tikka mild
2 paneer tikka paneer Punjab butter chicken medium
3 paneer tikka paneer Punjab paneer tikka mild
4 samosa potato Haryana butter chicken medium
5 dal makhani lentils Punjab butter chicken mediumThis tutorial codeswithpankaj covers the fundamental aspects of merging, joining, concatenating, and comparing DataFrames in Pandas. These operations are crucial for data manipulation tasks and provide flexibility in handling diverse datasets. Practice with various examples to master these techniques and enhance your data analysis skills